

The tech titan’s latest transparency report reveals the takedown pleas it’s received thus far.
Google has received 2.4 million “right to be forgotten” requests since 2014, most of which came from private individuals, according to its latest transparency report. Europe’s biggest court passed the right to be forgotten law in 2014, compelling the tech titan to remove personal info from its search engine upon request. In the report, Google has revealed that it complied with 43.3 percent of all the requests it’s gotten and has also detailed the nature of those takedown pleas.
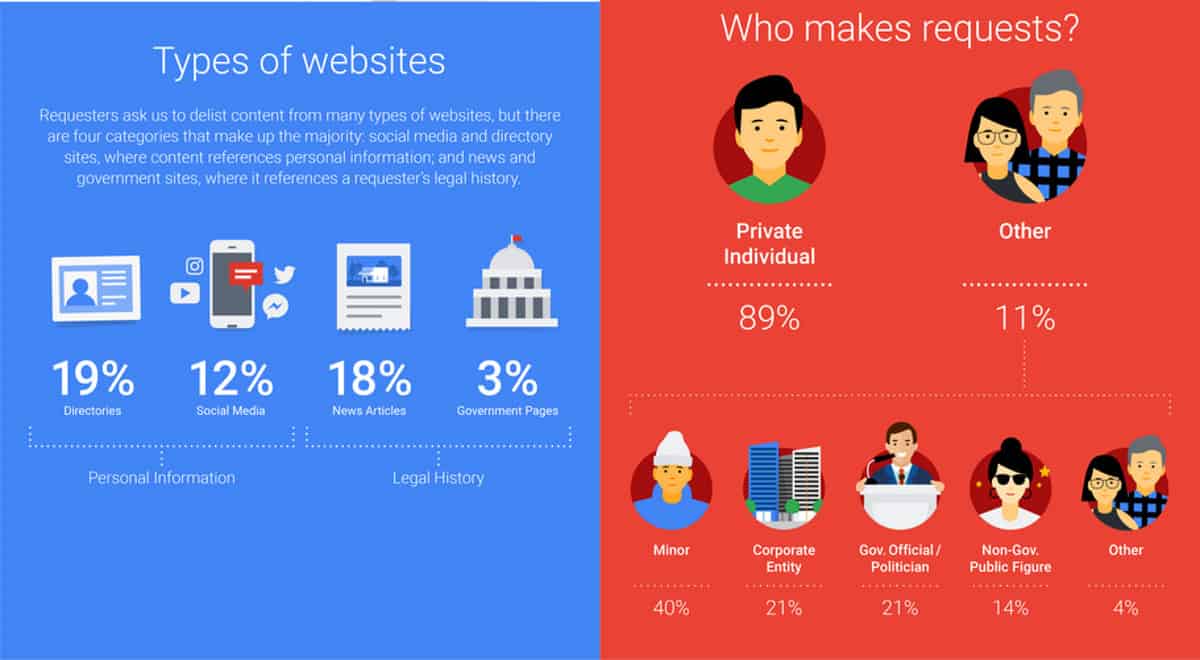
France, Germany and the UK apparently generated 51 percent of all the URL delisting appeals. Overall, 89 percent of the takedown pleas came from private individuals: Non-government figures such as celebrities submitted 41,213 of the URLs in Google’s pile, while politicians and government officials submitted 33,937. As Gizmodo noted, though, there’s a small group of law firms and reputation management services submitting numerous pleas, suggesting the rise of reputation-fixing business in the region.
Out of those 2.4 million requests, 19.1 percent are directory URLs, while news websites and social networks only make up 17.6 and 11.6 percent of them. Majority of the URLs submitted for removal are random online destinations that don’t fall under any of the previous categories. As for the takedown’s reasons, it looks 18.1 percent of the submissions want their professional info scrubbed, 7.7 percent want info they previously posted online themselves to be removed and 6.1 percent want their crimes hidden from search.
If you’re wondering why Google only complied with less than half of the takedown pleas it received and want to know how to submit a successful request, take this info into account:
A few common material factors involved in decisions not to delist pages include the existence of alternative solutions, technical reasons, or duplicate URLs. We may also determine that the page contains information which is strongly in the public interest. Determining whether content is in the public interest is complex and may mean considering many diverse factors, including—but not limited to—whether the content relates to the requester’s professional life, a past crime, political office, position in public life, or whether the content is self-authored content, consists of government documents, or is journalistic in nature.”
We’ll find out more about what the law thinks Google should and shouldn’t remove once the tech titan faces a couple of lawsuits filed against it in London. Two individuals want the company to remove URLs that have something to do with their previous convictions from search, and the first trial is scheduled to be heard today, February 27th.